

What is AI for business process automation? It is the strategic deployment of machine learning and cognitive agents to seamlessly execute complex, unstructured enterprise workflows. However, achieving this at scale requires replacing static legacy systems with dynamic, low-latency IT infrastructure.
TL;DR:
- Traditional rule-based automation runs on static infrastructure, whereas AI requires dynamic compute power and high-throughput data pipelines.
- Upgrading to active data lakes and low-latency storage is non-negotiable to prevent AI timeout errors and data bottlenecks.
- Highly regulated enterprises must weigh data sovereignty risks carefully, making managed private clouds the safest option for sensitive workloads.
- Avoiding vendor lock-in requires designing architecture-agnostic environments built on open standards.
For the past few years, enterprise IT and operations leaders have been sold a promise: deploy artificial intelligence into your workflows, and watch your operational costs plummet. Yet, when scaling these tools beyond a pilot program, many organizations hit a wall. Workflows freeze. Hallucinations spike. Cloud egress costs spiral out of control.
The harsh reality is that AI-powered business process automation rarely fails because the Large Language Model or the software itself is flawed. It fails because standard enterprise infrastructure was never designed to handle the massive, unstructured data throughput that cognitive tools require. If you are serious about maximizing efficiency and cost saving through business process optimization, you cannot simply layer next-generation software over last-generation infrastructure.
This guide cuts through the software hype to examine the hidden infrastructure layer, specifically the hardware, network, and storage foundations, that determines whether your enterprise AI deployment will scale gracefully or collapse under its own weight.
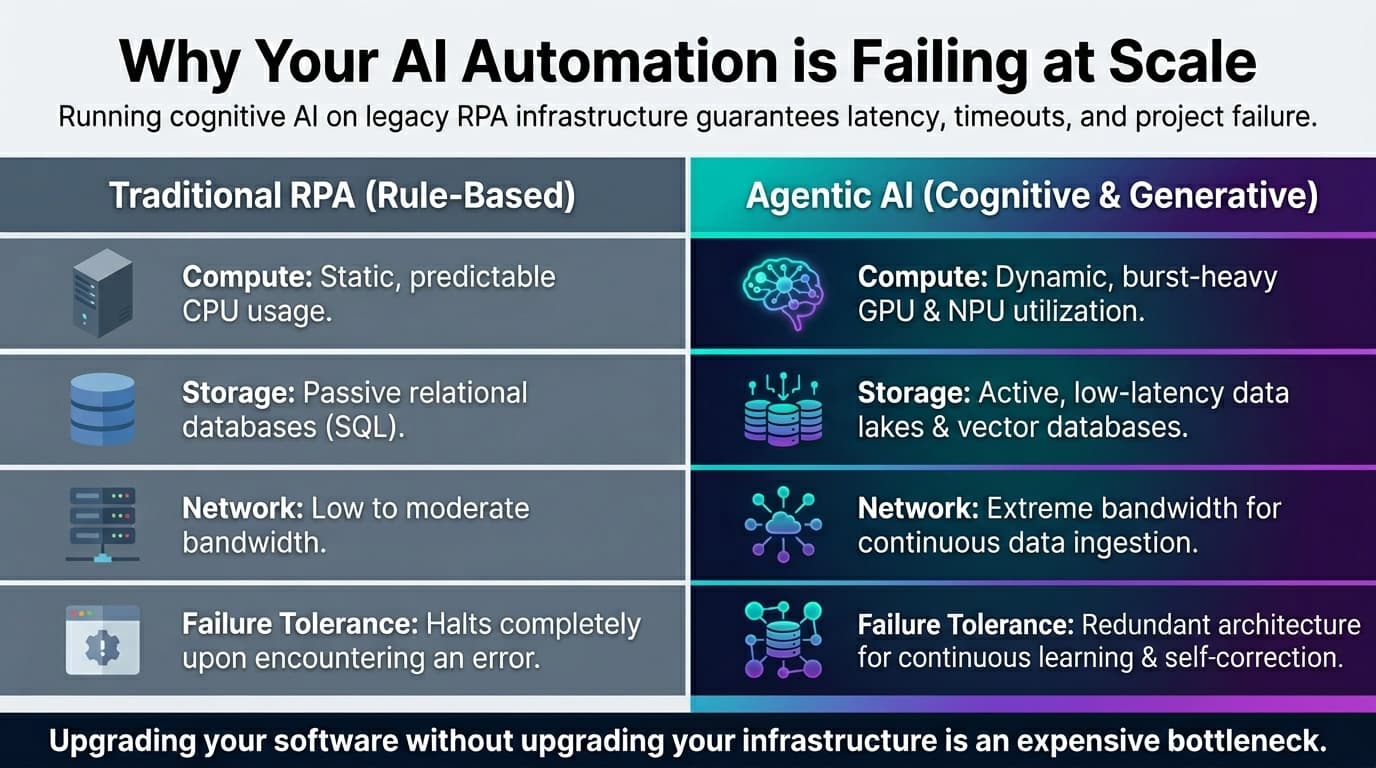
Traditional RPA vs. Agentic AI: Why the Backend Must Change
To understand the infrastructure shift required, we first need to clarify the fundamental difference between traditional Robotic Process Automation (RPA) and modern, agentic AI workflows.
Traditional RPA is essentially a fast, obedient worker following a strict, pre-determined script. It runs perfectly fine on predictable virtual machines with standard storage. Agentic AI, however, requires cognitive processing. It reads unstructured data, makes probabilistic decisions, and queries massive databases in real-time.
Here is how the infrastructure requirements differ between the two:
- Compute Resources: RPA relies on static, predictable CPU usage. AI demands dynamic, burst-heavy GPU or NPU utilization.
- Storage Architecture: RPA uses passive relational databases. AI requires active, low-latency data lakes and vector databases.
- Network Throughput: RPA operates on low to moderate bandwidth. AI needs extreme bandwidth for continuous data ingestion.
- Failure Tolerance: RPA halts upon encountering an error. AI requires redundant architecture to allow for continuous learning and self-correction loops.
When enterprise leaders attempt to run cognitive agents on infrastructure built for static RPA, the result is latency. In AI, latency leads to timeout errors where the AI simply gives up on a task, leaving human operators to clean up the mess. To prevent this, organizations must transition toward dedicated AI infrastructure services that provide the dynamic compute and fluid data mobility these advanced applications crave.
The Big Three: What Enterprise AI Workflows Actually Require
Whether you are deploying intelligent document processing for global trade compliance or integrating AI-driven process mining across your supply chain, your underlying architecture must master three critical domains. Without these, even the best AI software will falter.
1. Throughput & Latency: The Data Pipeline Problem
Generative AI and machine learning models are starved for context. To make an automated decision, such as approving a complex vendor invoice, the AI must instantly cross-reference unstructured emails, historical ERP data, and current compliance guidelines.
This creates a massive data pipeline problem. If your storage arrays suffer from high latency, the AI cannot retrieve the necessary vectors fast enough. This bottlenecking limits the volume of processes you can automate concurrently. Upgrading to high-throughput, low-latency network fabrics ensures that data flows seamlessly between the compute nodes and the storage arrays, enabling real-time automated decision-making at an enterprise scale.
2. Storage Architecture: Moving to Active Data Lakes
Passive storage, where data sits idly waiting to be queried, is obsolete for modern automation. AI business process automation requires an active storage architecture. Because AI tools continuously learn from new inputs, your storage must be capable of handling rapid read and write cycles of unstructured data like PDFs, audio logs, and video.
This requires a fundamental shift in accurate IT infrastructure capacity planning. IT leaders must design scalable data lakes that prevent data swamps, ensuring that information is properly indexed, tagged, and instantly retrievable by machine learning algorithms without dragging down the performance of the core network.
3. The Integration Layer: Connecting Legacy Systems
The most beautifully designed AI workflow is useless if it cannot communicate with your existing CRM or ERP system. Traditional API gateways are often too rigid and slow for the constant, micro-querying nature of AI agents.
A modern integration layer requires specialized middleware designed for high-concurrency connections. This ensures that when your AI tool needs to pull a customer record from SAP or push a billing update to Salesforce, it does not inadvertently trigger a Distributed Denial of Service effect on your own internal systems due to a flood of automated requests.
The Data Sovereignty Dilemma: On-Premise vs. Cloud AI Workflows
For global enterprises, particularly those based in highly regulated regions like Singapore operating across APAC and the US, AI introduces a severe data governance challenge. To achieve high-level automation, you must feed your most sensitive, proprietary data into the AI model.
If you rely entirely on public cloud hyperscalers for this processing, you risk violating data sovereignty laws, GDPR, or SOC2 compliance frameworks. Public clouds often process data across multiple geographic zones, creating a strict compliance nightmare for financial institutions, healthcare providers, and government-adjacent contractors.
This is where weighing cloud vs on-premise deployments becomes a critical board-level conversation.
When data sovereignty and intellectual property protection are non-negotiable, leaning entirely on public cloud AI services is a massive risk. In these scenarios, deploying a secure on-premise private cloud or a heavily localized, managed private environment becomes the only viable option. By keeping the compute and storage layers within your physical or jurisdictional control, you enable powerful AI automation without sacrificing security or regulatory compliance.
Designing Managed Cloud Infrastructure Without Vendor Lock-In
One of the most dangerous pitfalls of deploying AI for business process automation is infrastructure lock-in. Many software vendors and hyperscalers offer turnkey AI solutions, but these often trap your data inside their proprietary ecosystems. When you attempt to scale the automation or move your data out, you are hit with exorbitant egress fees and incompatible formatting.
Consider this scenario. A regional logistics firm headquartered in Singapore integrated a major hyperscaler’s AI document processing tool to automate customs declarations. As their volume scaled to millions of documents per month, their cloud egress and API compute costs skyrocketed by 400 percent. Because their infrastructure was deeply tied to that specific vendor’s proprietary database structure, migrating away would require months of downtime.
The solution is designing architecture-agnostic environments. This means building on open standards like OpenStack that allow you to port your workloads freely. For enterprise IT leaders exploring VMware alternatives in the wake of changing licensing models, this is the perfect time to rethink the backend.
By understanding the difference between managed vs cloud services, organizations can partner with managed cloud providers who build bespoke, highly interoperable environments. A tailored managed cloud gives you the raw compute power needed for AI without forcing you to surrender ownership of your architectural roadmap.
The AI-Ready Infrastructure Engagement: Scoping to Deployment
Transforming a legacy IT environment into an AI-ready powerhouse is not a mere upgrade; it is a strategic engagement. Organizations that succeed follow a strict, phased approach to ensure that the infrastructure supports the automation goals from day one.
- Workload Scoping: Before touching any hardware, analyze the exact data requirements of your chosen AI tools. Determine the required API calls per second, the average payload size, and the regulatory constraints of the data being processed.
- Architecture Design: Design a hybrid or private cloud blueprint that prioritizes low latency and high security. This is where decisions on SSD and NVMe storage arrays and dedicated network links are finalized.
- Interoperability Testing: Deploy the infrastructure in a sandbox environment and stress-test the integration layer between the AI tools and legacy ERP or CRM systems to identify bottlenecks.
- Full Deployment & Management: Roll out the infrastructure. Crucially, partnering with a managed IT services provider ensures continuous monitoring, patching, and capacity scaling. This takes the day-to-day burden off your internal IT team so they can focus on strategic innovation.
Conclusion
Great AI software running on poor infrastructure is nothing more than an expensive bottleneck. As business process automation evolves from simple, rule-based scripts to cognitive, generative workflows, the underlying hardware, network, and storage must evolve with it.
Enterprises that fail to upgrade their data pipelines, address sovereignty risks, and build architecture-agnostic environments will find their AI initiatives stalling at the pilot phase. However, those who treat infrastructure as the critical foundation of their automation strategy will unlock unprecedented efficiency and scale.
Do not let legacy architecture throttle your automation potential. Assess your environment, understand your workloads, and build a foundation capable of handling the future of enterprise AI.Ready to build the foundation for enterprise-scale AI? Assess your AI infrastructure readiness with a bespoke consultation today
Dandy Pradana is an Digital Marketer and tech enthusiast focused on driving digital growth through smart infrastructure and automation. Aligned with Accrets’ mission, he bridges marketing strategy and cloud technology to help businesses scale securely and efficiently.




