

AI IT operations, commonly referred to as AIOps or Event Intelligence Solutions, fundamentally rely on a unified, observable, and highly normalized infrastructure foundation to function. If you attempt to deploy artificial intelligence over fragmented networks and unstructured data logs, the software will fail to deliver actionable insights or reduce your operational burden. It is critical to standardize your environment and establish reliable multi-cloud connectivity before investing in AI tools.
TL;DR
- Artificial intelligence cannot fix a fundamentally broken or fragmented IT environment.
- Most AI IT implementations fail in the first six months due to poor data ingestion and fragmented monitoring tools.
- A unified observability layer and aggressive data normalization are non-negotiable prerequisites.
- You must audit and fix your infrastructure foundation first, and only then layer the AI tools on top.
AI in IT Operations (AIOps) is the application of artificial intelligence, machine learning, and big data analytics to automate and enhance IT infrastructure management. It proactively identifies issues, reduces alert noise, and accelerates incident resolution by analyzing massive volumes of operational telemetry data in real time.
For years, the technology sector has been flooded with vendor pitches promising that artificial intelligence will instantly cure your operational headaches. In fact, the landscape is evolving so rapidly that Gartner is officially rebranding AIOps to “Event Intelligence Solutions” (EIS) for 2025, signaling a shift toward more mature, action-oriented platforms.
But whether you call it AIOps or EIS, almost every software vendor and industry analyst misses the single most critical factor in a successful deployment: the hidden infrastructure dependency.
Artificial intelligence is not a magic wand you can wave over a chaotic data center. It is a highly sophisticated analytical engine that is entirely dependent on the underlying environment it monitors. If your networks, servers, and storage arrays are fragmented, your AI will be too. Before you invest in a shiny new platform for AI IT operations, you must first accept a hard truth: AI cannot fix a broken foundation; it can only tell you, with incredible speed and precision, exactly how broken it is.
The 6-Month Trap: Why Most AIOps Implementations Fail Early
There is a recurring pattern in enterprise IT that we call “shiny object syndrome.” An organization’s leadership, eager to modernize, purchases a top-tier AIOps platform. They expect an immediate reduction in downtime and a leap in operational efficiency. Yet, six months later, the IT team is still drowning in false positive alerts, the AI models are starved for reliable data, and the project is quietly deemed a failure.
Why does this happen? The failure rarely lies with the AI software itself. Instead, it stems from deploying advanced algorithms on top of an unprepared environment. When organizations attempt to implement AI without addressing the prerequisites, they inevitably hit three major roadblocks:
- Fragmented Environments: Many enterprises operate with a mix of legacy on-premises servers, multi-cloud deployments, and siloed departments. If your network team, storage team, and compute team are using entirely different, disconnected monitoring tools, the AI cannot form a cohesive understanding of your ecosystem.
- Data Ingestion Problems (Garbage In, Garbage Out): AI models require massive amounts of clean, structured data to establish a baseline of “normal” behavior. If your infrastructure generates erratic, unstructured, or incomplete telemetry, the AI will learn the wrong baseline, resulting in useless insights.
- Poor Baseline Observability: You cannot automate what you cannot see. If there are blind spots in your network, the AI cannot magically fill them in.
Overcoming these hurdles requires a strategic shift. Instead of treating AI as a standalone software purchase, leaders must view it as the final layer of comprehensive cloud operations management.
The Prerequisites: Building an AIOps-Ready Infrastructure
To ensure your Event Intelligence Solutions actually deliver ROI, you must build an environment that the AI can easily read, understand, and act upon. This means shifting your focus away from the application layer and down into the very bones of your data center.
Here are the non-negotiable infrastructure prerequisites you must establish before turning the AI on:
- A Unified Observability Layer: You must break down the traditional silos between compute, storage, and network domains. An AIOps-ready infrastructure utilizes a unified monitoring strategy where all components report telemetry to a centralized hub. This gives the AI a single source of truth rather than forcing it to decipher conflicting reports from disparate dashboards.
- Aggressive Data Normalisation: Raw logs and metrics come in countless different formats depending on the hardware vendor. Before AI can analyze this data, it must be parsed, cleaned, and normalized into a standard format. Your infrastructure architecture must include robust data pipelines designed specifically to prepare telemetry for machine learning ingestion.
- Reliable Monitoring Coverage: Blind spots are the enemy of predictive analytics. You need end-to-end monitoring that covers everything from your core switches to your edge devices. If a critical server goes down but was not properly instrumented, the AI will be just as surprised as your human engineers.
- Seamless Multi-Cloud Connectivity: Modern enterprises rarely exist in a single environment. Your private infrastructure, public cloud instances, and edge locations must communicate seamlessly. The network architecture connecting these environments must be resilient and low-latency, ensuring that telemetry data flows uninterrupted to the AI engine.
Achieving this level of standardization is not a trivial task, which is why establishing these foundational elements remains one of the top 3 best practices for IT infrastructure management today.
What “AIOps-Ready” Looks Like in Practice (Real-World Patterns)
When an enterprise gets the foundation right, the transformation is palpable. But what does this actually look like in the real world, devoid of vendor marketing speak?
In a traditional, reactive IT setup, engineers spend their days chasing alerts. A database slows down, triggering a CPU alert on the server, a latency alert on the storage array, and a packet drop alert on the network switch. The engineers scramble to piece together the root cause manually.
In contrast, an “AIOps-ready” environment is clean and quiet. Because the infrastructure was standardized and integrated before the AI was deployed, the system functions as a single organism. When that same database slows down, the infrastructure’s unified telemetry allows the AI to instantly correlate the storage, compute, and network data, presenting the engineer with a single, actionable ticket: “Database latency caused by failing drive in Array B; failover initiated.”
Building this level of maturity often requires outside expertise. Organizations frequently realize that their internal teams are too busy keeping the lights on to fundamentally rearchitect the environment. In these cases, a specialized Managed Service Provider (MSP) acts as the architect, objectively assessing the environment and building the foundation. This is a critical step in establishing a resilient corporate IT infrastructure in Singapore: the blueprint for mid-size enterprises and global organizations alike.
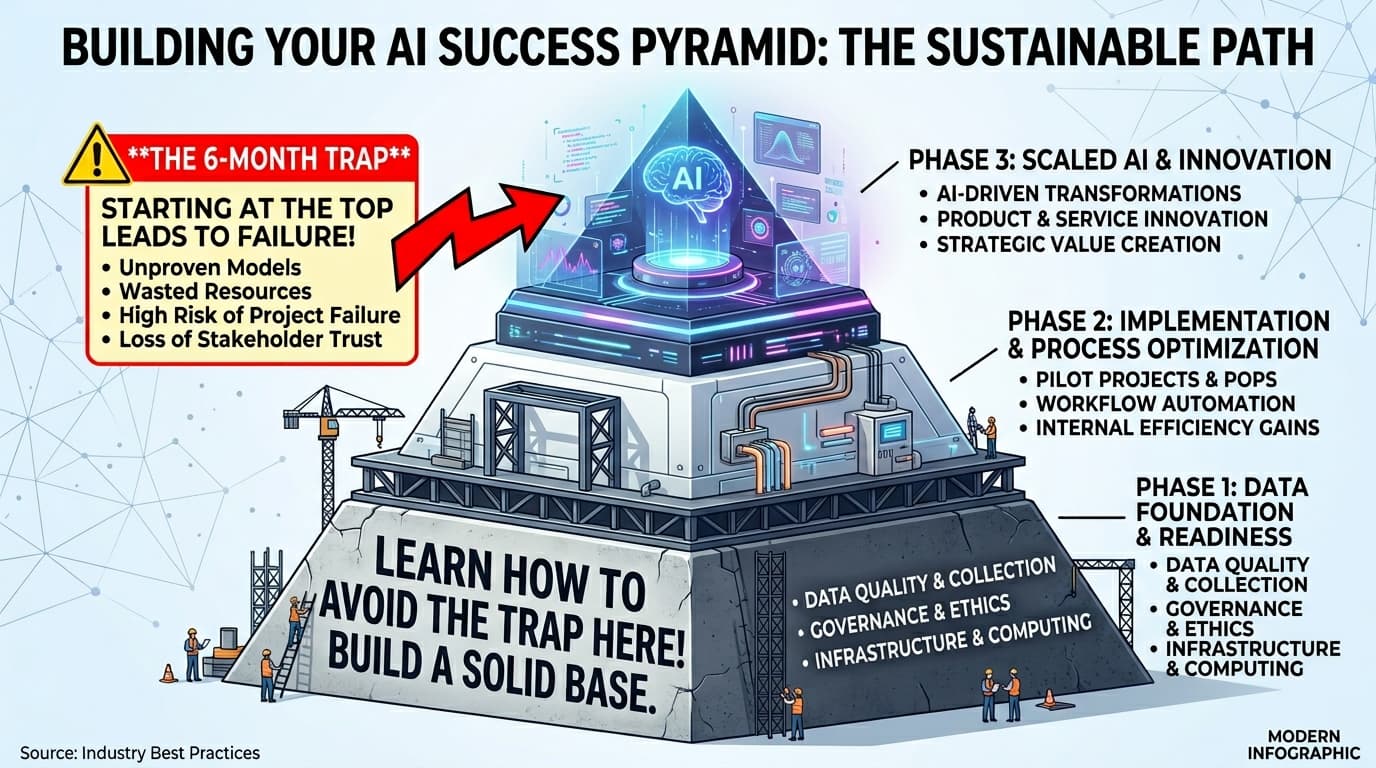
The Implementation Sequence: Fix the Foundation, Then Layer the AI
Adopting AI for IT operations is a journey, not a single installation event. To avoid the 6-month trap, leaders must enforce a strict implementation sequence. Do not buy the AI license until you have completed the first two phases.
Phase 1: Infrastructure Audit and Remediation
Begin with a ruthless assessment of your current state. Identify hardware approaching the end of life, locate monitoring blind spots, and document every siloed tool currently in use. The goal of Phase 1 is to simplify and consolidate. Retire redundant monitoring tools and upgrade legacy systems that cannot generate modern telemetry.
Phase 2: Establishing Unified Data Pipelines
Once the environment is clean, build the plumbing. Implement centralized logging and robust data normalization processes. This is the phase where you ensure that all infrastructure components are speaking the same language. You are not running AI yet; you are simply proving that you can reliably collect and structure your operational data.
Phase 3: Layering the Event Intelligence Solutions
Only when you have clean, unified, and reliable telemetry should you introduce the AI platform. Because you have provided a perfect foundation, the AI’s machine learning models will rapidly establish accurate baselines, leading to immediate, high-quality insights.
Executing this sequence requires discipline, and many organizations choose to partner with experts in IT infrastructure managed services to ensure the remediation and data pipeline phases are executed flawlessly.
The True ROI: What AI IT Operations Delivers on a Solid Foundation
When you respect the implementation sequence and prioritize infrastructure readiness, the business outcomes are profound. AIOps shifts from being an expensive experiment to a core driver of operational excellence.
With a solid foundation, AI IT Operations realistically delivers:
- Massive MTTD and MTTR Reduction: Mean Time To Detect and Mean Time To Resolve are drastically slashed. Because the AI has access to normalized data from across the entire infrastructure, it can pinpoint root causes in seconds, entirely bypassing the traditional human troubleshooting process.
- The Elimination of Alert Fatigue: Human engineers are no longer bombarded with thousands of meaningless warnings. The AI filters out the noise, correlates related events, and escalates only genuine, actionable incidents. This improves team morale and frees up your best talent for strategic projects.
- Predictive Capacity Management: Rather than waiting for a server to run out of storage and crash, the AI analyzes historical utilization trends against current demands. It can predict exactly when you will run out of resources weeks in advance, allowing for proactive, stress-free IT infrastructure capacity planning.
How to Assess Your Infrastructure Readiness for AI
Before you engage with software vendors selling the promise of autonomous IT, you must look inward. Is your data clean? Is your environment unified? Are your monitoring tools providing a complete picture, or just fragmented snapshots?
If you try to bolt AI onto a fragile infrastructure, the AI will fail. The smartest move an IT leader can make today is to step back, evaluate the underlying architecture, and do the hard work of building a resilient foundation.
If you are unsure whether your environment is ready to support advanced Event Intelligence Solutions, do not guess. Get an objective, expert assessment of your current architecture and your multi-cloud connectivity.
Talk to an infrastructure specialist about your AI readiness today.
Dandy Pradana is an Digital Marketer and tech enthusiast focused on driving digital growth through smart infrastructure and automation. Aligned with Accrets’ mission, he bridges marketing strategy and cloud technology to help businesses scale securely and efficiently.




